Hidden in Plain State : Empoisonner les LLMs Hybrides Là Où Personne Ne Regarde (1/3)
Les LLMs hybrides comme Qwen3.5 mélangent l'attention classique avec des couches récurrentes. J'ai découvert que corrompre l'état récurrent, invisible pour tous les outils de monitoring, cause un déraillement silencieux du modèle pendant la génération.

Les modèles hybrides arrivent en production. Qwen3.5, la dernière famille open-weight d’Alibaba, mélange l’attention softmax classique avec Gated DeltaNet, un mécanisme récurrent qui compresse le contexte dans une matrice d’état de taille fixe au lieu de faire grandir un KV cache. L’architecture est élégante : trois couches récurrentes pour l’efficacité, puis une couche d’attention complète comme “checkpoint” pour rattraper les erreurs. Et ainsi de suite.
J’ai passé les dernières semaines à poser une question simple : que se passe-t-il quand on corrompt la partie que personne ne surveille ?
La réponse est pire que ce que j’imaginais.
Travaux antérieurs & ce qui manque
Les attaques au niveau de l’état sur les modèles séquentiels sont assez récentes. HiSPA (Le Mercier et al., Jan 2026) a démontré l’empoisonnement du hidden state contre Mamba, montrant que seulement 6 tokens suffisent à écraser la mémoire d’un SSM. MTI (Hossain et al., Jan 2026) a exploré la corruption du KV cache comme surface adversariale. CacheSolidarity (Pennas et al., Mar 2026) a étudié la sécurité du prefix caching, mais uniquement pour les KV caches classiques.
Le plus pertinent pour ce travail est CLASP (Le Mercier et al., publié 5 jours avant que j’écrive ces lignes), qui propose une défense contre HiSPA spécifiquement pour les architectures hybrides. CLASP entraîne un classifieur XGBoost sur les embeddings de sortie de blocs, le hidden state h à chaque frontière de couche, pour détecter les tokens adversariaux injectés dans le prompt. Il atteint un F1 token-level de 95.9% sur les modèles Mamba, Samba et Zamba. Vous ne comprenez rien ? C’est normal, mais n’hésitez pas à revenir consulter cette section et les travaux liés après avoir fini votre lecture.
Mon travail a été mené indépendamment de CLASP et adresse un modèle de menace différent. CLASP défend contre les attaques black-box au niveau du prompt : des tokens malveillants qui corrompent l’état via des passes forward normales. J’étudie la corruption directe de l’état, spécifiquement ce qui se passe quand un attaquant modifie le recurrent state S lui-même via un cache d’inférence partagé. La détection de CLASP repose entièrement sur la surveillance de h. Comme je vais le montrer ci-dessous, corrompre S laisse h complètement intact pendant le prefill. CLASP ne verrait rien.
Plus largement, ce que personne n’a encore étudié, c’est l’interaction entre la persistance du recurrent state et le prefix caching multi-tenant en production. Qwen3.5 est le premier modèle majeur avec cette architecture hybride, déployé via vLLM avec le prefix caching activé par défaut. Le recurrent state S est un nouvel objet dans la pile d’inférence, et aucune défense existante ne le couvre parce que la surface d’attaque n’avait pas été caractérisée.
C’est cette caractérisation. Ou plutôt, le premier de trois articles de blog à ce sujet.
L’architecture : 3 récurrentes, 1 attention, repeat
Avant de plonger, laissez-moi clarifier les deux types de couches en jeu ici.
L’attention complète est le mécanisme qui a rendu les transformers célèbres. Autrement dit, c’est ce qu’utilise votre LLM préféré ! Pour chaque token de la séquence, le modèle calcule un score de similarité avec tous les autres tokens, puis mélange leurs valeurs proportionnellement. C’est puissant mais coûteux : le calcul et la mémoire croissent de façon quadratique avec la longueur de séquence. En échange, chaque token peut directement porter attention à tous les autres, ce qui en fait le gold standard pour la précision.
Gated DeltaNet (GDN) adopte une approche différente. Au lieu de garder l’historique complet des interactions entre tokens (le Key Value cache), il compresse tout ce qu’il a vu jusqu’ici dans une seule matrice de taille fixe appelée S. Chaque nouveau token met à jour S en écrivant de nouvelles informations et en faisant décroître les anciennes. C’est beaucoup moins cher (linéaire au lieu de quadratique), mais la compression est lossy. Les informations plus anciennes peuvent être écrasées ou oubliées.
Sur leur dernier modèle, Qwen a décidé de combiner les deux : trois couches GDN pour l’efficacité, puis une couche d’attention complète pour “regarder tout” et corriger les erreurs accumulées. Par exemple, le modèle 4B que j’ai utilisé pour les premières expériences a 32 couches, organisées en 8 blocs de ce type (24 couches GDN, 8 “checkpoints” en attention complète). En gros, plus le modèle est gros, plus il y a de couches. Sur le 27B, il y a 64 couches.
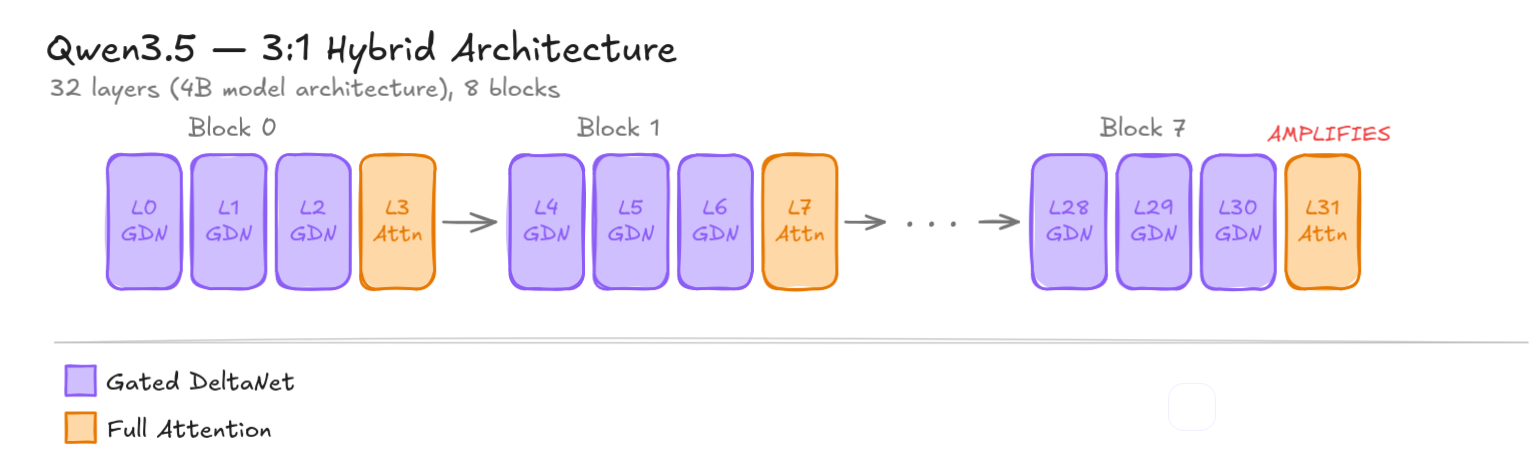 Le pattern d’entrelacement 3:1 de Qwen3.5. Les couches GDN (violet) maintiennent un état récurrent ; les couches Full Attention (ambre) agissent comme des checkpoints périodiques.
Le pattern d’entrelacement 3:1 de Qwen3.5. Les couches GDN (violet) maintiennent un état récurrent ; les couches Full Attention (ambre) agissent comme des checkpoints périodiques.
Ce design introduit deux états internes complètement différents :
h, le hidden state. C’est le vecteur d’activation standard qui traverse chaque couche, GDN et attention complète confondues. Il a pour shape [batch, seq_len, 4096]. Si vous surveillez les internals du modèle (ce que font la plupart des frameworks de sécurité), vous regardez h. Le corrompre produit une baisse immédiate et mesurable de la cosine distance à chaque couche en aval.
S, le recurrent state. Celui-ci n’existe que dans les couches GDN. C’est le résumé compressé de tout ce que le modèle a vu jusqu’ici, stocké sous forme de matrice de shape [batch, 32_heads, 128, 128], environ 512 Ko par couche. Pendant la phase de prefill (traitement du prompt), S est calculé en même temps que les sorties. Pendant la génération (production de nouveaux tokens), S est lu token par token. Cette distinction va devenir critique.
Bon, je suis pas sûr de pas vous avoir perdus là… c’est peut-être trop abstrait à comprendre. Alors voici un petit dessin au cas où vous vous sentiriez largués !
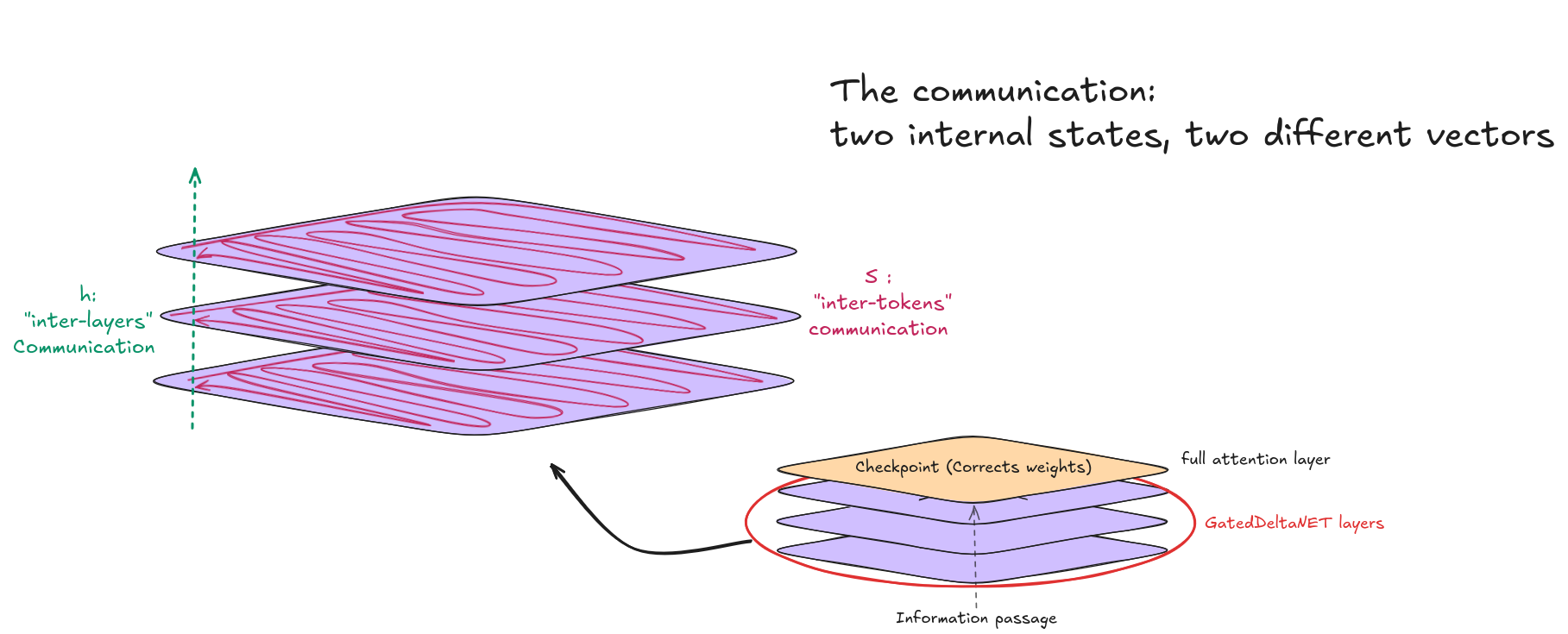 Les deux sont complémentaires, h a besoin de S pour transférer l’information tandis que S n’a pas de sens sans h.
Les deux sont complémentaires, h a besoin de S pour transférer l’information tandis que S n’a pas de sens sans h.
La mise à jour d’état GDN suit la règle delta :
1
S_t = alpha * S_{t-1} - beta * S_{t-1} * k * k^T + beta * v * k^T
Le terme -beta * S * k * k^T est la correction delta, censée corriger les erreurs en projetant les informations obsolètes le long de la direction des clés avant d’écrire de nouvelles données. C’est ce qui rend GDN plus robuste que Mamba (son “prédécesseur”), qui n’a aucun terme de correction.
Mais la correction a un angle mort. La matrice S est organisée en lignes qui correspondent aux clés (quoi chercher) et en colonnes qui correspondent aux valeurs (quoi récupérer). La correction delta fonctionne en vérifiant : “est-ce que l’ancien état contient déjà quelque chose stocké sous une clé similaire ?” Si oui, elle supprime l’entrée obsolète avant d’écrire la nouvelle.
Le problème, c’est que cette vérification ne se fait que le long de la dimension des clés. Si la corruption entre par la dimension des valeurs (le contenu réel stocké en mémoire, pas l’adresse de recherche), la règle delta n’a aucun mécanisme pour la détecter ou la corriger. Ce serait comme un système de classement qui empêche les noms de dossiers en double mais ne vérifie jamais si quelqu’un a échangé les documents à l’intérieur.
Imaginez S comme une grille. Les lignes sont des adresses ; les colonnes sont les données stockées à ces adresses. La correction delta est un correcteur orthographique qui ne lit que les étiquettes d’adresse. Si vous vous infiltrez et réécrivez les données derrière une adresse valide, le correcteur vous fait un pouce levé — l’adresse a l’air correcte.
Sur le modèle 9B, l’espace des clés fait 2048 dimensions mais l’espace des valeurs en fait 4096. Ça signifie que 67% de la matrice d’état vit dans des dimensions que le mécanisme de correction ne peut pas atteindre. Sur le 27B, l’espace des valeurs monte à 6144 dimensions tandis que les clés restent à 2048, poussant la surface non corrigée à 75%. Plus le modèle est gros, plus l’angle mort est grand.
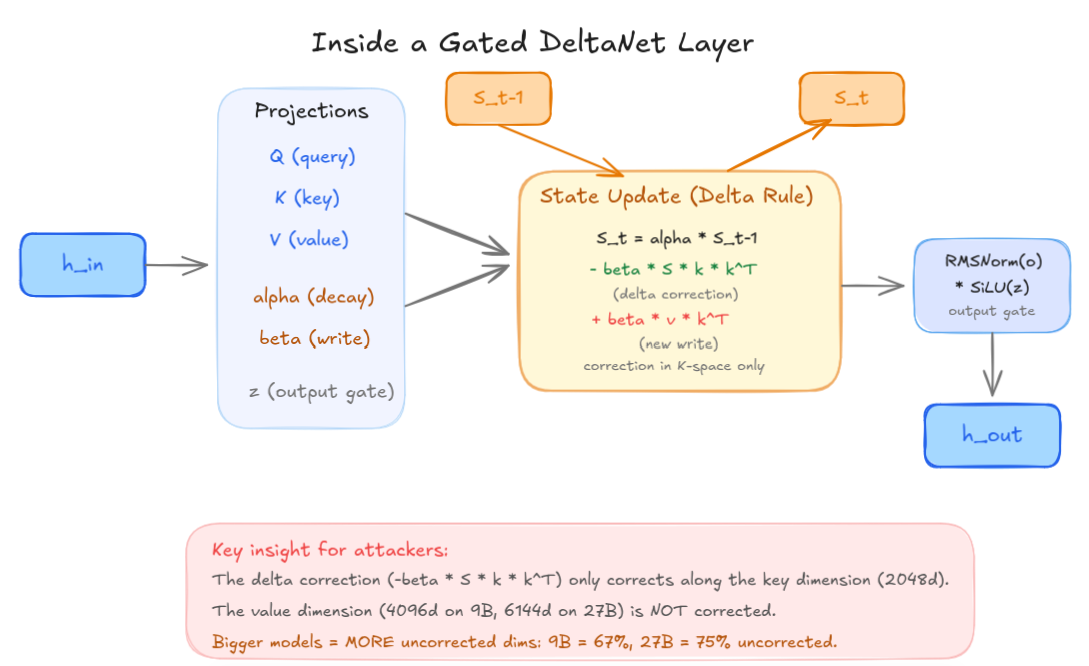 Anatomie d’une couche GDN. Le terme de correction delta opère exclusivement dans le K-space, laissant le V-space, plus grand, sans protection.
Anatomie d’une couche GDN. Le terme de correction delta opère exclusivement dans le K-space, laissant le V-space, plus grand, sans protection.
h-perturbation : la surface évidente
La première expérience naturelle : injecter du bruit gaussien dans le hidden state h à différentes couches et magnitudes, puis mesurer à quel point la sortie finale change. J’ai testé ça sur 10 prompts divers (factuel, code, chinois, nonsense, répétitif) sur Qwen3.5-4B.
Le seuil de 0.1%
Il faut étonnamment peu de bruit pour corrompre les couches GDN. Le seuil à partir duquel la corruption devient mesurable est epsilon = 0.001, soit 0.1% de la norme du hidden state. Pour référence, à epsilon = 0.01 (1%), une injection GDN à la couche 0 fait chuter la cosine similarity à L31 à 0.504 (essentiellement un pile ou face entre la représentation propre et corrompue), tandis que le même bruit sur une couche d’attention complète (L3) ne la fait descendre qu’à 0.800.
| epsilon | L0 (GDN) cos@L31 | L3 (FullAttn) cos@L31 |
|---|---|---|
| 0.001 | 0.987 | 0.997 |
| 0.005 | 0.757 | 0.916 |
| 0.01 | 0.435 | 0.652 |
Cosine similarity à la couche finale après injection de bruit. Prompt : tokens nonsense à haute entropie (pire cas). Plus c’est bas, plus la réponse est corrompue. Toute la génération utilise le greedy decoding (do_sample=False), pas de temperature, pas de top-p, seed 42 pour la reproductibilité des perturbations. Quantification NF4 sur RTX 4060 8 Go ; validation BF16 sur Mac Studio M4.
La valeur d’epsilon représente la magnitude de la perturbation relative à la norme du hidden state de la couche. Concrètement : si le vecteur h à la couche L0 a une norme L2 = 12.0, alors epsilon = 0.01 signifie que j’ajoute un vecteur de bruit gaussien de norme L2 = 0.12. Douze centièmes d’unité, et la représentation interne du modèle est à moitié détruite le temps qu’elle sorte du réseau.
Des modes de défaillance qualitativement différents
C’est là que ça devient intéressant. Les couches GDN et d’attention complète ne diffèrent pas juste en fragilité ; elles cassent de manières fondamentalement différentes.
À epsilon = 0.01, l’injection dans une couche GDN (L0) produit une destruction totale du signal :
- Prompt Eiffel →
".........A.A.A.A.A.A.A.A" - Prompt répétitif →
"of of of of of of..." - Prompt nonsense →
",JcAJcAJcAJcAJcA..."
L’injection dans une couche d’attention complète (L3) produit des hallucinations cohérentes :
- Prompt Eiffel →
"100% tax on buildings" - Prompt répétitif → génération inchangée (bruit entièrement absorbé)
- Prompt nonsense →
".00000000000000..."
La corruption GDN annihile le signal. La corruption par attention complète le dévie. Et dans un cas, les tokens répétitifs “ignore” à L3, la couche d’attention complète a simplement absorbé 1% de bruit sans aucun effet observable.

Les checkpoints ne checkpointent pas…?
La promesse architecturale centrale du design 3:1 est que les couches d’attention complète agissent comme une correction d’erreur périodique. Toutes les quatre couches, le modèle a la possibilité de “tout regarder à nouveau” et de corriger la dérive accumulée des couches récurrentes.
En pratique, ça n’arrive jamais.
J’ai injecté du bruit à L9 (milieu du réseau, dans la fenêtre de vulnérabilité où la decay gate g est la plus proche de zéro). La corruption se propage :
1
2
3
4
5
6
L9 (inject) → cosine 1.000
L10 (GDN) → cosine 0.538 ← immediate corruption
L11 (ckpt) → cosine 0.519 ← checkpoint makes it WORSE
L15 (ckpt) → cosine 0.498 ← still worse
L19 (ckpt) → cosine 0.495 ← still worse
L31 (ckpt) → cosine 0.742 ← partial recovery, still broken
Pas un seul checkpoint n’a réduit la corruption. Plusieurs l’ont amplifiée. Le checkpoint final à L31 est particulièrement préoccupant : sur les 10 prompts de test, il a amplifié la perturbation 100% du temps, avec des augmentations de norme allant de +25% à +125%.
Les “checkpoints” ne sont pas des checkpoints. Ce sont des amplificateurs.
Ce que la h-perturbation nous apprend
Ces résultats sont alarmants mais finalement gérables du point de vue défensif. La h-perturbation est visible : n’importe quel moniteur de cosine similarity sur les couches intermédiaires détecterait l’anomalie immédiatement. La corruption est détectable parce qu’elle se propage à travers le même tenseur que tous les outils de monitoring existants surveillent.
Si c’était toute l’histoire, les implications sécuritaires seraient gérables. On ajouterait un hook de monitoring, on fixerait un seuil, et c’est réglé.
Ce n’est pas toute l’histoire.
Le twist : S-perturbation
J’ai lancé la même expérience, mais au lieu de corrompre le hidden state h, je me suis concentré sur le recurrent state S.
Même couche. Même epsilon. Même prompt.
Pendant le prefill (traitement du prompt d’entrée à travers les 32 couches), la cosine similarity entre les hidden states propre et corrompu à L31 était :
1.0000.
Pas 0.99. Pas 0.999. Un point zéro zéro zéro zéro. Le monitoring du hidden state ne voit littéralement rien. La perturbation est invisible. Cachée en pleine lumière.
Puis le modèle commence à générer.
Le modèle propre génère : “Paris, France. The Eiffel Tower is a famous landmark…”
Le modèle corrompu sur S génère : “Paris. How many different types of cakes can you make?”
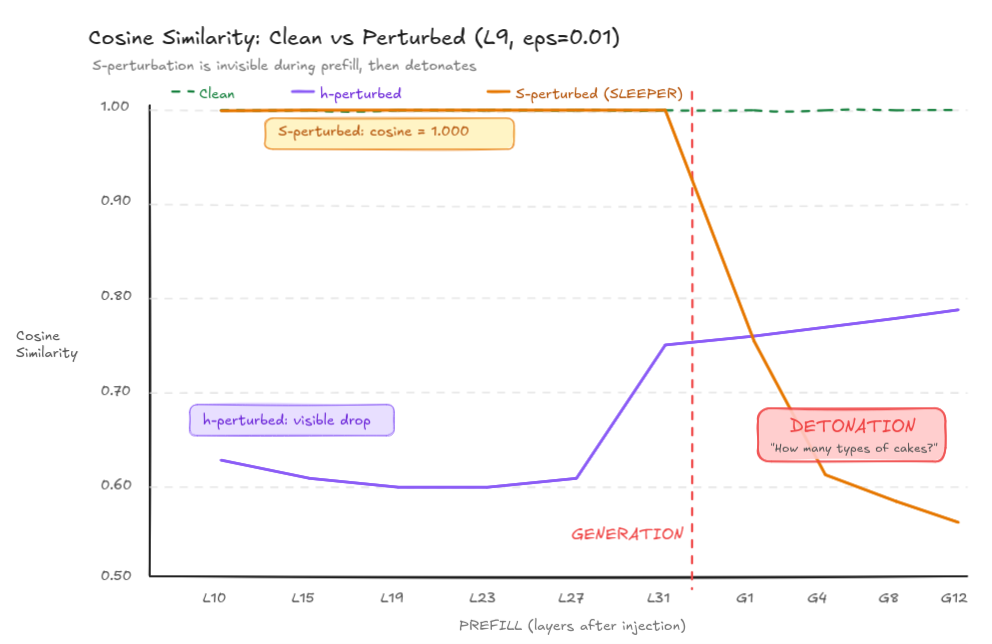 Le moment clé. Pendant le prefill (à gauche de la ligne rouge), la S-perturbation est complètement invisible, cosine = 1.000. À l’instant où la génération commence, l’état corrompu détone.
Le moment clé. Pendant le prefill (à gauche de la ligne rouge), la S-perturbation est complètement invisible, cosine = 1.000. À l’instant où la génération commence, l’état corrompu détone.
Pourquoi ça se produit
L’asymétrie vient de la façon dont le kernel GDN gère le prefill versus la génération.
Pendant le prefill, chunk_gated_delta_rule traite tous les tokens en chunks parallèles. Il calcule S et les sorties de couche simultanément à partir des tokens d’entrée. La perturbation de S n’affecte que la valeur finale de S ; elle ne modifie pas rétroactivement les sorties qui ont déjà été calculées pendant le prefill. Les hidden states passent sans être modifiés.
Pendant la génération, recurrent_gated_delta_rule passe en mode séquentiel. Chaque nouveau token lit depuis S pour calculer sa sortie, puis met à jour S. Le S corrompu influence maintenant directement chaque token généré. Le sleeper se réveille.

Le scénario d’attaque
Ça crée une attaque de cache poisoning propre :
- L’attaquant corrompt S dans un prefix cache partagé (par ex, un system prompt mis en cache par vLLM pour du serving multi-tenant)
- La requête d’une victime touche le préfixe mis en cache. Le monitoring voit des hidden states normaux, la cosine similarity est parfaite
- Les tokens de la victime commencent à être générés. La corruption de S s’active. Le modèle hallucine, déraille, ou boucle
- Aucune alarme ne se déclenche. Aucune métrique ne spike. La corruption est invisible pour toute approche de monitoring standard
Et contrairement à la h-corruption (qui produit du charabia), la S-corruption produit quelque chose de bien plus difficile à détecter : un déraillement sémantique. Le modèle ne crashe pas. Il change de sujet en douceur.
En tout cas, c’est ce qui est théoriquement possible. Ce serait dommage que ce soit déjà en production… ^^”
Six mémoires, six façons de casser
La matrice S de chaque couche GDN encode un aspect différent du contexte. J’ai vérifié ça en corrompant S une couche à la fois et en observant des modes de défaillance qualitativement différents :
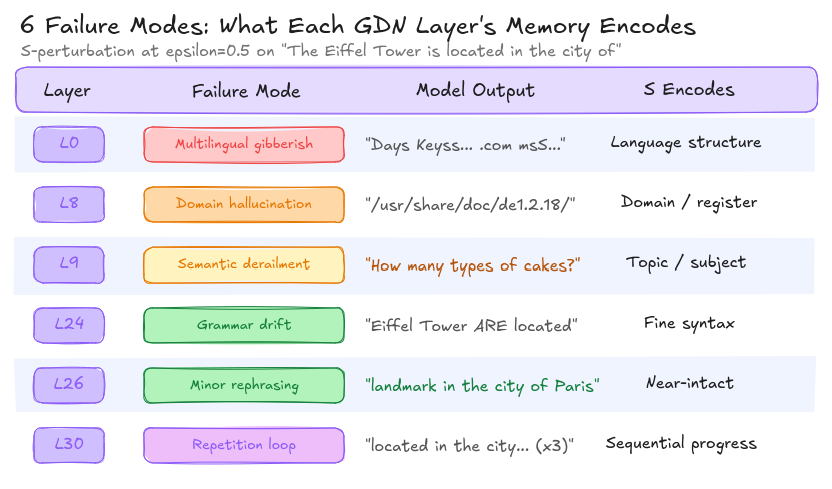 Chaque couche GDN stocke une “mémoire” différente. L0 contient la structure linguistique. L9 contient le sujet. L30 contient la progression séquentielle. Corrompre chacune casse le modèle d’une manière distincte et prédictible.
Chaque couche GDN stocke une “mémoire” différente. L0 contient la structure linguistique. L9 contient le sujet. L30 contient la progression séquentielle. Corrompre chacune casse le modèle d’une manière distincte et prédictible.
Ce n’est pas juste du bruit qui produit des sorties aléatoires. Le S de la couche 0 encode dans quelle langue on parle. Le S de la couche 9 encode de quoi on parle. Le S de la couche 30 encode où on en est dans la séquence. Chacun peut être ciblé chirurgicalement.
Le plus dangereux du point de vue d’un attaquant est L9, le déraillement sémantique. Le modèle ne produit pas du charabia (qui serait détecté par les filtres de perplexité). Il ne produit pas d’erreurs factuelles (qui seraient détectées par le fact-checking). Il se met simplement… à parler d’autre chose. Dans un contexte d’entreprise où un LLM traite des milliers de requêtes par heure, combien de temps avant que quelqu’un remarque que les réponses parlent de gâteaux au lieu de coûts d’infrastructure ?
h et S : deux surfaces d’attaque orthogonales
Les expériences de perturbation ont révélé quelque chose de structurellement élégant et profondément préoccupant. La surface de vulnérabilité s’inverse entre les deux états :
| h-perturbation | S-perturbation | |
|---|---|---|
| Timing | Immédiat | Différé (prochain token généré) |
| Détectable | Oui (monitoring cosine) | Non (cosine = 1.0 pendant le prefill) |
| Meilleure cible | L26 (haute norme, profond) | L0 (plus haute norme S : 25.7) |
| Pire cible | L0 (faible norme) | L26 (S à peine utilisé) |
| Mode de défaillance | Charabia / crash | Déraillement sémantique / boucles |
| Scénario d’attaque | Injection de prompt en temps réel | Cache poisoning, multi-tenant |
La couche qui est la plus vulnérable à la h-corruption (L26) est la moins vulnérable à la S-corruption, et inversement. Ce sont des surfaces orthogonales. Se défendre contre l’une n’aide pas contre l’autre.
Le seuil de corruption est le même pour les deux : epsilon = 0.001 (0.1% de la norme de l’état). La différence réside entièrement dans la détectabilité.
Une note sur la quantification
Ces premières expériences ont été menées sur Qwen3.5-4B en quantification NF4 (pour tenir dans un GPU de 8 Go de vRAM). J’ai ensuite validé les résultats clés en BF16 sur un Mac Studio M4 Max, la précision utilisée dans les déploiements de production. L’effet sleeper et la taxonomie des modes de défaillance se maintiennent. Certains seuils bougent : le BF16 est plus robuste au bruit aléatoire, comme attendu d’une arithmétique de plus haute précision. Je couvrirai les nuances de quantification et le scaling cross-modèle dans la Partie 2.
La suite
J’ai ensuite lancé ces mêmes expériences sur le 9B et le 27B.
Le résultat m’a surpris. On s’attendrait à ce que les plus gros modèles soient plus robustes : plus de paramètres, plus de redondance, plus de capacité à absorber le bruit. Et pour la h-perturbation, c’est exactement ce qui se passe. Le 9B et le 27B encaissent sans broncher des h-attacks optimisées par gradient qui éventrent le 4B.
Mais pour la S-perturbation, le scaling va dans l’autre sens. Le 27B investit plus dans son recurrent state (norme de S à L0 : 25.7 sur le 4B, 119 sur le 9B, 204 sur le 27B). Cet investissement plus grand crée une dépendance plus grande. Et une dépendance plus grande crée une surface d’attaque plus grande.
Plus gros, c’est plus sûr pour l’état que tout le monde surveille.
Plus gros, c’est plus dangereux pour l’état que personne ne surveille.
La Partie 2 sort la semaine prochaine.